Baseline Models
Contents
Overview
This project aims to identify if self-supervised learning is a viable option when training on satellite imagery with limited access to labeled data. Our baseline models are trained on various neural network architectures and fractions of labeled data to quantify the performance impact as our fraction of labeled data changes. We will use the baseline models' results to assess the performance of our self-supervised models with the same labeling constraints.
Before diving into the models, it is essential to understand the methodology for applying the “irrigated” label. Using the Big Earth Net labels, we identified two different methods to determine irrigation state. We will refer to these methods as regular labels or expanded labels (described below) in our experiments.
- Regular Labels: Regular labels take the “permanently irrigated” label from Big Earth Net data and use it as the ground truth for classification. All images that do not include this label are part of the negative class.
- Expanded Labels: When analyzing the Big Earth Net labels, some of them corresponded to croplands that would imply irrigation. We used these additional labels to broaden what the definition of irrigated is to include the following: Fruit trees and berry plantations, rice fields, vineyards, olive groves, and permanently irrigated.
In addition to the different labeling methods, we also trained the models in two ways; full training or ImageNet pre-training. The full training experiments train a model from scratch using various fractions of labeled data. The ImageNet pre-training starts off the training with pre-trained weights from an ImageNet model. It is important to note that models trained with ImageNet weights are only trained on RGB channels, while training from scratch utilizes all available channels.
Baseline models were trained on the following architectures.
- InceptionV3
- ResNet101V2
- ResNet152
- ResNet50
- Xception
Full training
Models were trained from scratch on each architecture and labeling methodology.
Regular Labels
Supervised model with various splits of labeled data. For the first set of experiments we used only the “permanently irrigated” label for classification, which is only a small fraction of the dataset at roughly 2.3%. We explore models commonly trained with the ImageNet dataset, and several ResNet models of different sizes, on ever diminishing splits of our labeled dataset.
| Split | InceptionV3 | ResNet101V2 | ResNet152 | ResNet50 | Xception |
|---|---|---|---|---|---|
| 100% | 0.93925 | 0.93450 | 0.915600 | 0.93275 | 0.93975 |
| 50% | 0.93550 | 0.90925 | 0.936516 | 0.90650 | 0.93875 |
| 25% | 0.89875 | 0.92050 | 0.907726 | 0.91900 | 0.92925 |
| 10% | 0.78500 | 0.89825 | 0.885581 | 0.82050 | 0.89625 |
| 3% | 0.85025 | 0.83450 | 0.811024 | 0.77100 | 0.65925 |
| 1% | 0.56800 | 0.52425 | 0.777067 | 0.52225 | 0.49975 |
Interestingly, as shown more readily in Figure 1 there is a large variance in model performance for ResNet152 and other models. This variance was not consistent and is likely explained by randomness in models with very small data sets. Sometimes the models would perform much better than others which may just be chalked up to luck.
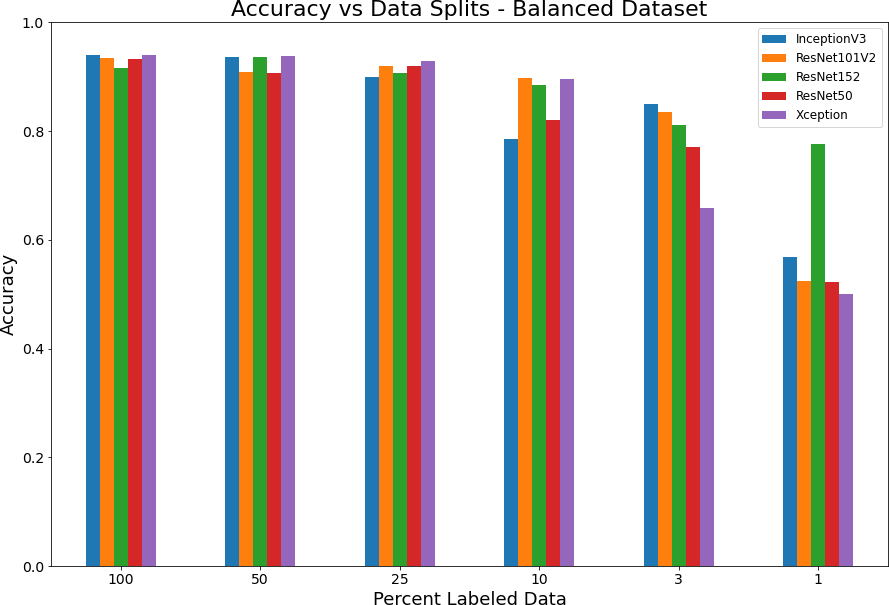
Figure 1: Accuracy versus data splits for full model with regular labels
Expanded Labels
Supervised model with various splits of labeled data. In Addition to the “permanently irrigated” we also include Vineyards, Rice fields, fruit orchards and olive groves, which now represents approximately 6.24% of the dataset.
| Split | InceptionV3 | ResNet101V2 | ResNet152 | ResNet50 | Xception |
|---|---|---|---|---|---|
| 100% | 0.888028 | 0.856050 | NaN | 0.859056 | 0.885477 |
| 50% | 0.873269 | 0.819424 | 0.836826 | 0.863794 | 0.847577 |
| 25% | 0.850856 | 0.837008 | 0.851130 | 0.847303 | 0.840835 |
| 10% | 0.835550 | 0.847030 | 0.842839 | 0.813138 | 0.844479 |
| 3% | 0.824071 | 0.817420 | 0.801840 | 0.831906 | 0.830357 |
| 1% | 0.805029 | 0.808582 | 0.554391 | 0.559311 | 0.627187 |
As stated above, it appears that randomness in the training has produced models with a large variance in accuracy for the 1 percent data split. Another interesting observation with using the expanded labels is that model performance improves quickly as opposed the more expected logarithmic curve exhibited when training with regular labels.
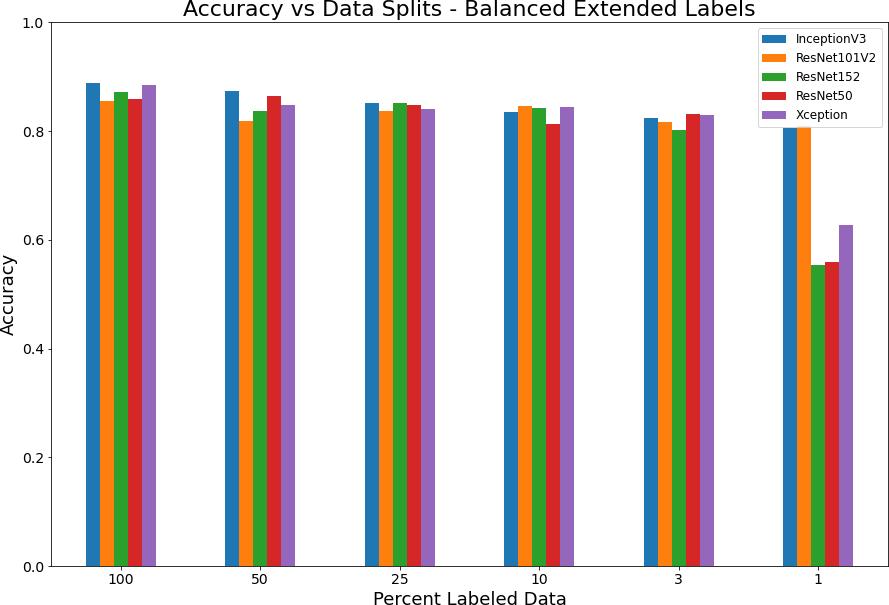
Figure 2: Accuracy versus data splits for full model with expanded labels
ImageNet Pretraining
Models were trained on each architecture and labeling methodology using weights from ImageNet as a starting point. When using ImageNet weights the models were only trained on RGB channels.
Regular Labels
Supervised model with various splits of labeled data. Used only the “permanently irrigated” label for classification but trained only on the RGB channels using ImageNet weights.
| Split | InceptionV3 | ResNet101V2 | ResNet152 | ResNet50 | Xception |
|---|---|---|---|---|---|
| 100% | 0.85600 | 0.88225 | 0.816929 | 0.82875 | 0.89575 |
| 50% | 0.85425 | 0.88475 | 0.790600 | 0.81050 | 0.88525 |
| 25% | 0.84125 | 0.85025 | 0.789616 | 0.81700 | 0.87650 |
| 10% | 0.82425 | 0.73550 | 0.725640 | 0.78925 | 0.83625 |
| 3% | 0.81675 | 0.84250 | 0.760827 | 0.77600 | 0.84625 |
| 1% | 0.77875 | 0.78150 | 0.704724 | 0.76625 | 0.82575 |
The ImageNet weights seem to produce more consistency in the models across all data splits but does not achieve the same accuracy as the full models as the fraction of labeled data increased. The Xception architecture was the best performing across all data splits.
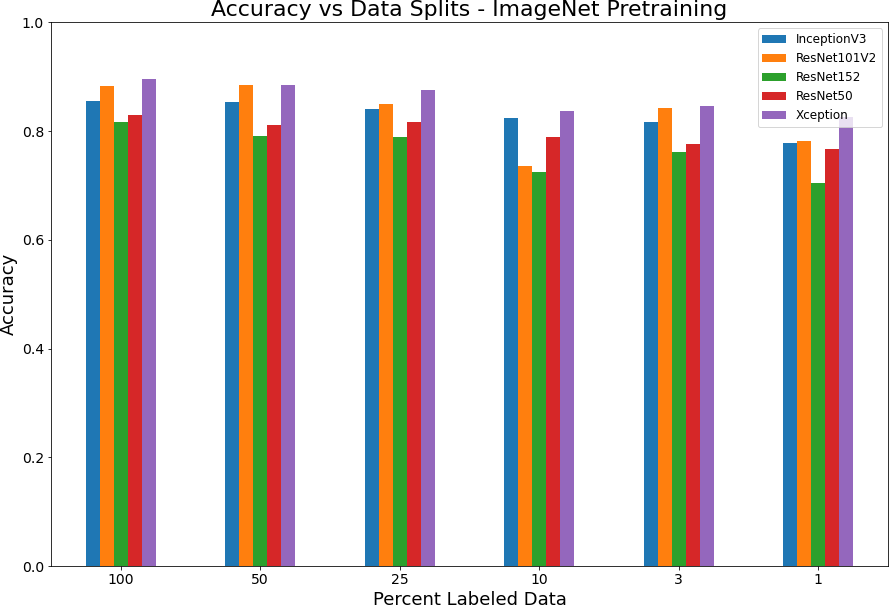
Figure 3: Accuracy versus data splits for pretrained model with regular labels
Expanded Labels
Supervised model with various splits of labeled data. Used expanded labels (permanently irrigated, Vineyards, Rice fields, fruit orchards and olive groves) for classification but trained only on the RGB channels using ImageNet weights.
| Split | InceptionV3 | ResNet101V2 | ResNet152 | ResNet50 | Xception |
|---|---|---|---|---|---|
| 100% | 0.821793 | 0.846028 | 0.792821 | 0.793003 | 0.845117 |
| 50% | 0.811224 | 0.834001 | 0.784803 | 0.794734 | 0.845208 |
| 25% | 0.802660 | 0.829173 | 0.775237 | 0.763575 | 0.828626 |
| 10% | 0.743349 | 0.783710 | 0.754100 | 0.760933 | 0.822522 |
| 3% | 0.741345 | 0.780703 | 0.752278 | 0.720390 | 0.806214 |
| 1% | 0.777332 | 0.769133 | 0.737518 | 0.717474 | 0.784074 |
The performance with this experiment is very similar to the regular labels with the Xception model appearing to be the best.
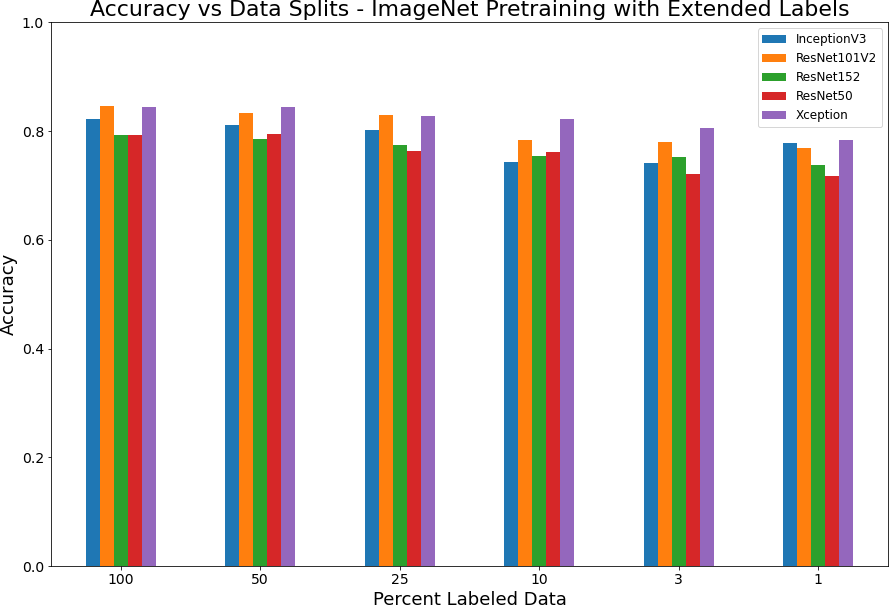
Figure 4: Accuracy versus data splits for pretrained model with expanded labels