SimCLR-S2 Stage 2: Fine-Tune
Contents

Training
In this post, we will explore the second phase of the SimCLR methodology, fine-tuning. This phase will use the contrastive model generated from the pre-training step as a starting point to train a supervised model with a smaller labelled dataset specific to the task as hand. We experiment with various size of balanced labeled data generated by under sampling the original BigEarthNet-S2 dataset.
We start the fine tuning step with 3 different SimCLR-S2 pretrained models. For each model, we perform supervised training with 6 different data sizes, each with 2 different class labeling schemes, giving us 36 experiments in all.
Fine-tuning a pretrained model requires loading one of the three pretrained models, and freezing all but the last two layers in the projection head (aka fully connected layers).
Datasets
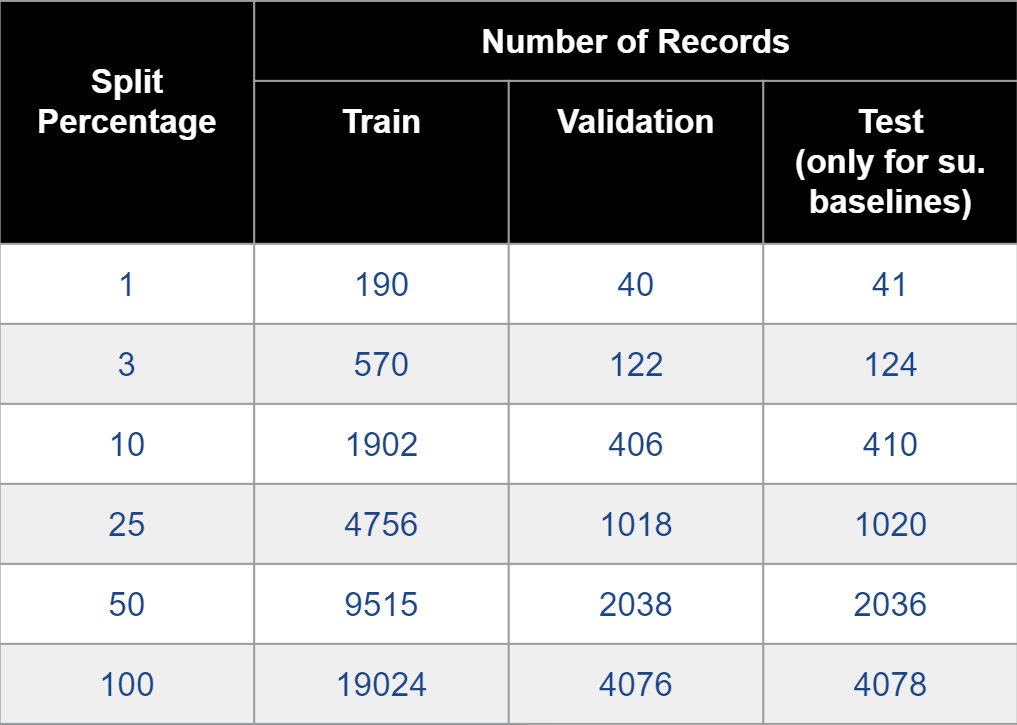
Since fine-tuning requires labels, all three pretrianed networks used a portion of the BigEarthNet-S2 dataset. As we mentioned in our EDA sections, there is a very small percentage of images labelled as irrigated, roughly 13.5 thousand images, and so care was taken when generating these split percentage datasets to incorporate an equal share of irrigated vs non-irrigated images. We also divide the percentage datasets into 70/15/15 train, validation and test splits, and image counts are shown in the following table:
Comparisons
Our fine tuning results showed that the SimCLR-S2 models performed on par or better than the supervised baseline models for the smaller data sizes. As shown below, performance of the supervised baseline models catches up and often surpasses our fine-tuned model at higher percent splits.
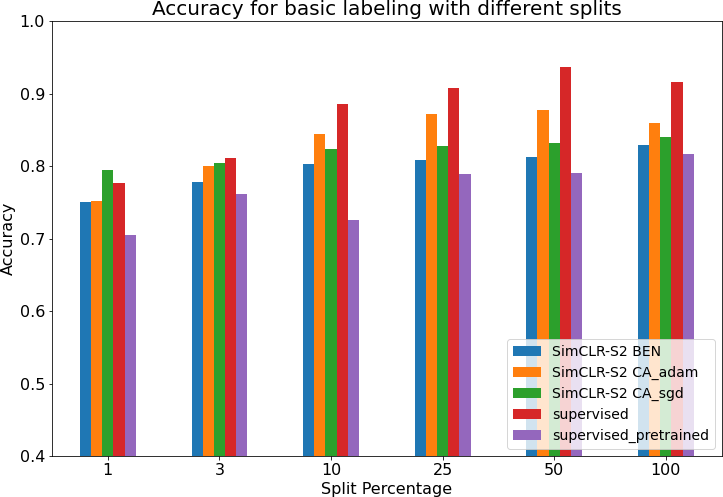
Figure 1: Finetune accuracy for various models

Figure 2: Finetune F1 Scores for various models