About
Contents
Purpose
As the global population grows, so does agricultural demand. The increase in demand must be monitored carefully since agricultural production relies on delivering water to croplands. In California, for example, more than nine million acres of farmland are irrigated, which represents roughly 80% of all water used for businesses and homes. Accurately measuring current and anticipated water needs is critical to ensure that water resources are allocated appropriately.
Historically, monitoring water usage has been a slow and expensive manual process. As technology has evolved, we see ourselves in a situation where we can leverage satellite imagery and computer vision techniques to classify land areas associated with agriculture and irrigation infrastructure. This technology has undoubtedly increased the velocity at which we can monitor irrigation patterns, but the need for labeled data requires manual effort and is a bottleneck. This project aims to leverage new capabilities in the computer vision space to classify irrigation in satellite images with a minimal amount of labeled data.
Contrastive Learning
The core methodology of our training will leverage contrastive learning to generate a self-supervised model. While typical machine learning models leverage labeled data to identify features associated with a label, contrastive learning aims to identify similarities. The basic approach used to train a computer vision model is to apply augmentations to an image and apply a loss function to minimize the distance between images of the positive class and maximize the distance of all other images.
The basic process is to apply random augmentations such as crop, blur, rotation, etc., to a batch of N images, resulting in a training data set of 2N images. Each image in the training set has a corresponding augmented image, and the pair is referred to as the “positive” class. All other images in the training corpus are part of the “negative” class. This process is outlined in Figure 1.
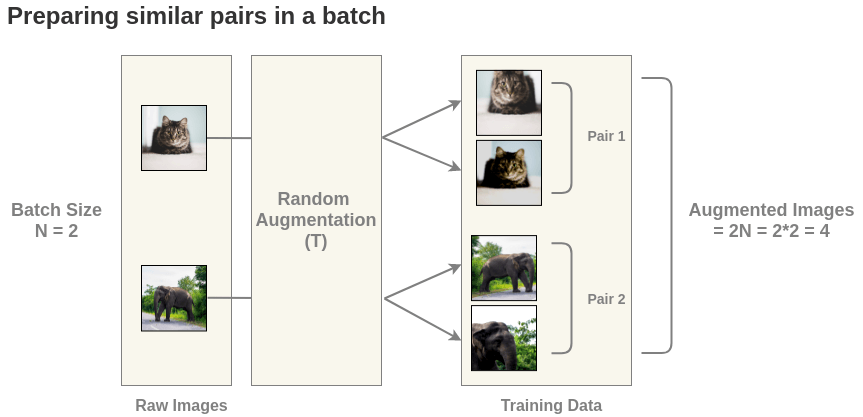
Figure 1: SimCLR batch data preparation
As the contrastive model learns, it will attempt to “attract” the positive class and “repel” the negative class to ultimately generate a model that maximizes the distance between positive and negative classes. The loss function is based on cosine similarity and is described by the following equation.
$$l_{i,j} = -{log} \frac{exp(sim(z_i,z_j)/\tau)}{\sum_{k=1}^{2N}1_{k \ne i} exp(sim(z_i,z_j)/\tau))}$$
The animation in Figure 2 illustrates, at a high, the steps performed during contrastive learning.
- Start with a batch of unlabeled images
- Randomly transform each image
- Pass images through CNN encoder
- Pass encoded images through MLP projection head
- Compute loss

Figure 2: Contrastive learning methodology
SimCLRv2 Framework
Contrastive learning is just one piece of the puzzle needed to complete the task of labeling irrigated land. The result of training with contrastive learning yields a model that can detect similarity in an image, but it cannot classify it. This is where the SimCLR approach comes into play. There are two versions of SimCLR, and version 2 is the current state of the art, so it will be the version used to build the irrigation classification model.
At a high level, the SimCLR can be broken down into three steps: unsupervised pre-training, supervised fine-tuning, and distillation. The training pipeline is shown in Figure 3.
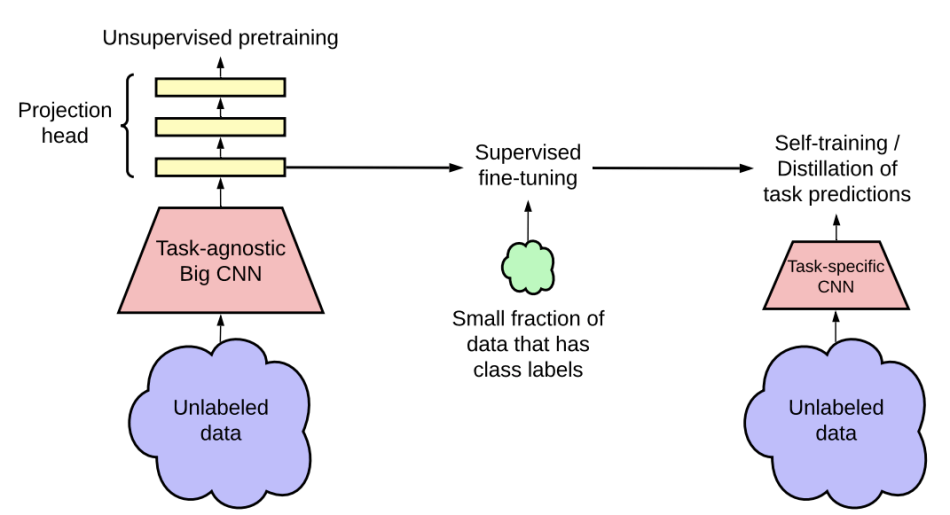
Figure 3: SimCLR version 2 process
Unsupervised Pretraining
Unsupervised pretraining leverages the contrastive learning approach described previously. In this phase, a corpus of images is obtained, and a model is generated to identify similarities of images. The pretraining is most effective when performed on a large CNN architecture such as ResNet-152. The key here is that all training is done on an entirely unlabeled dataset.
Supervised Fine-Tuning
Fine-tuning is the phase that trains the classification model. The process of fine-tuning leverages the unsupervised model as a starting point. A small number of labeled images train the unsupervised model at the classification task. The important takeaway with this approach is that leveraging the self-supervised model as a starting point should yield a model that has comparable accuracy to a supervised model with a fraction of the labeled data.
Distillation
The goal of the distillation phase is to shrink the model size while maintaining similar performance. As stated above, the unsupervised model performs best when trained on a large model with many parameters. The ideal state is to achieve the best performance with the smallest model. A student/teacher methodology trains the smaller model based on labels imputed by the fine-tuned model.
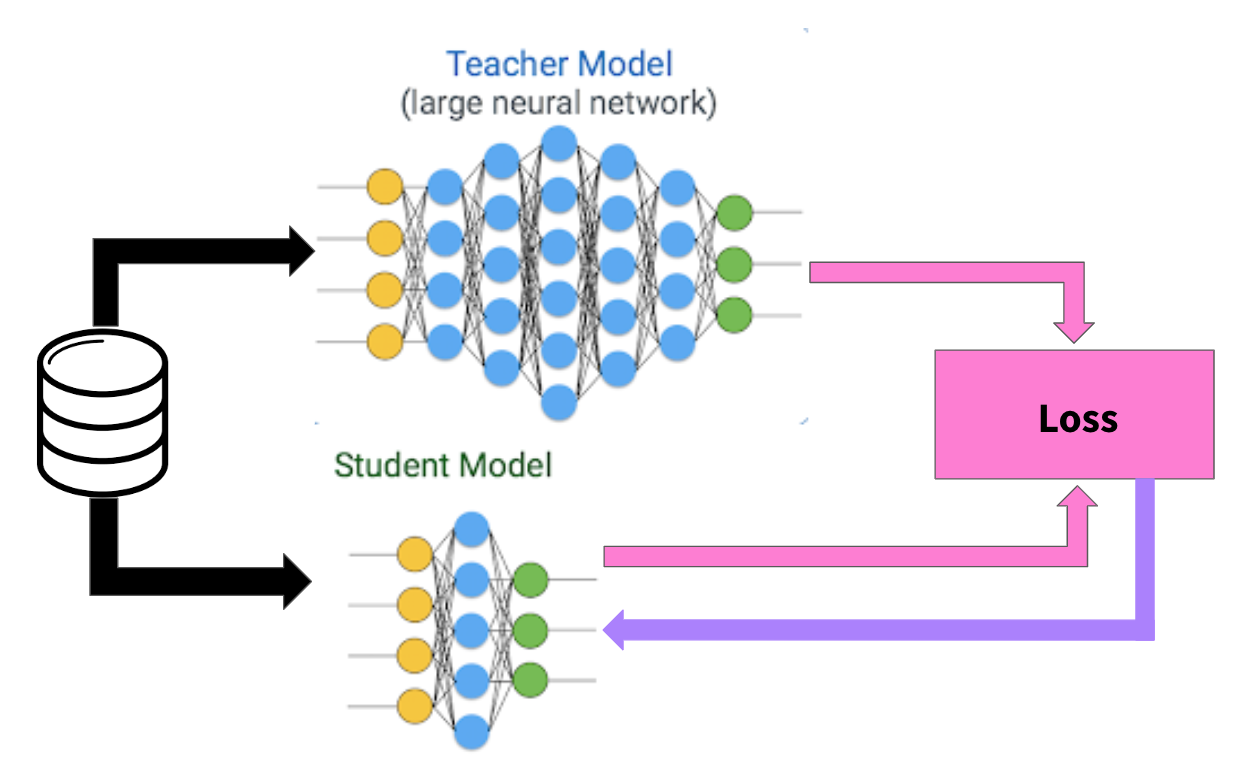
Figure 4: SimCLR student/teacher knowledge distillation
The distillation process, like the pre-training, is performed on an unlabeled data set. To train the student model, we use the fine-tuned model to label each training image. The smaller student model then learns based on the labels imputed by the teacher. The goal is to maximize the agreement between the student and the teacher. An important note here is that since the labels are not a ground truth, over-fitting the student model is not a concern.
Why SimCLR-S2
The dataset used to classify irrigated land in this project are satellite images in the Sentinel-2 format. These images are much different from a typical image since there are 12 channels instead of the standard 3 RGB channels we expect when working with images. The original SimCLR research used ImageNet with only RGB channels. Since we use a different data format, we thought it fitting to name our experiment SimCLR-S2 to determine if the SimCLR technique is effective with the Sentinel-2 image format.